

Dynamiczny zapis danych z XML do listy SharePoint
Table of Contents
W poprzednim poście opisywałem rozwiązanie umożliwiające dynamiczne tworzenie list SharePoint oraz ustawianie ich uprawnień. Chcę jednak podzielić się również rozwiązaniem, które pozwoli Ci tworzyć elementy list dynamicznie, dla danych pochodzących z XML.
Idea
Celem tego rozwiązania jest umożliwienie dynamicznego tworzenia elementów list SharePoint z wykorzystaniem danych XML jako danych wejściowych. Dzięki temu kolumny istniejące na liście SharePoint zostaną wypełnione powiązanymi danymi z pliku XML. Wystarczy do tego kilka kroków!
Wyobraź sobie, że masz plik XML będący wynikiem wypełnionego formularza online i musisz zapisać jego dane na liście SharePoint. W najlepszym scenariuszu każdemu polu w formacie XML odpowiada odpowiednia kolumna na liście SharePoint. Ale co jeśli nie? Istnieją dwa scenariusze:
- Dane z pola nie powinny być zapisywane w SharePoint,
- Należy dynamicznie stworzyć nową kolumnę do przechowywania danych z pola.
W tym poście chciałbym się skupić na pierwszym scenariuszu.
Dlaczego?
Ano dlatego, że to co Ci zaprezentuję to rozwiązanie bardzo elastyczne i niewymagające stosowania pętli „Apply to each”. Tak więc, jeśli nie ma kolumny dla pola, właściciel listy musi ją po prostu dodać, ale do tego czasu proces może zostać pomyślnie ukończony w ciągu zaledwie kilku sekund.
Jak dane są zapisywane do SharePoint?
W tym celu korzystam z poniższej metody do tworzenia elementu, używając (moim zdaniem) mało znanego endpointa:
_api/web/lists/GetByTitle('LIST NAME')/AddValidateUpdateItemUsingPath
(Źródło: Working with lists and list items with REST | Microsoft Learn).
Endpoint nie tylko umożliwia tworzenie elementów w podfolderach list programu SharePoint (czego nie jest w stanie zrobić zwykły endpoint tworzenia elementów), ale także sprawia, że jest to naprawdę szybkie.
Mapowanie XML do JSON
Pierwszym krokiem jest pobranie danych z XML i zmapowanie ich do zwykłego formatu JSON, który może być bezpośrednio użyty w requeście skierowanym do endpointa REST SharePoint. Struktura XML może być płaska lub zagnieżdżona. W tym przypadku konstrukcja jest prosta:
<root>
<field-one>Some value</field-one>
<field-two>Some other value</field-two>
<some-other-field>Some another value</some-other-field>
...
</root>
Aby to uzyskać, najpierw konwertuję tekst z pliku XML z base64 na prawidłowy plik XML, a następnie pobieram wszystkie elementy z pliku XML. Na koniec konwertuję go na prawidłowy JSON:
json(xpath(xml(base64ToString('XML FILE CONTENTS')), '/root/*'))
Usuwanie nie-istniejących pól
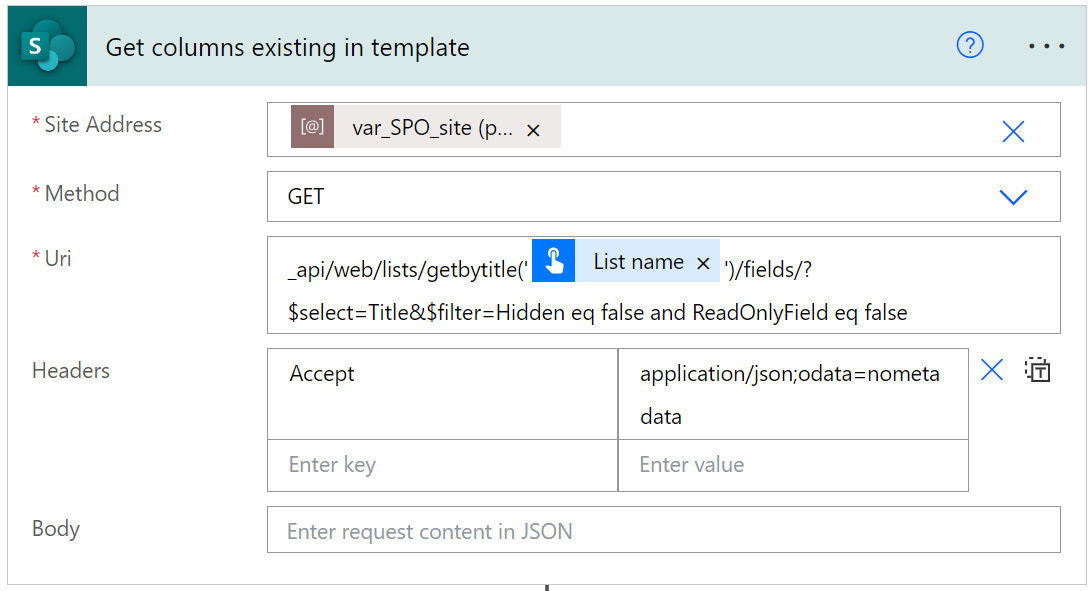
Następnie, aby uniknąć błędów podczas wysyłania kodu JSON do endpointa, muszę usunąć z niego te pola, które nie występują jako kolumny. Aby to osiągnąć, najpierw wykonuję zapytanie do endpointa:
_api/web/lists/getbytitle('LIST NAME')/fields/?$select=Title&$filter=Hidden eq false and ReadOnlyField eq false
By pobrać listę wszystkich customowych kolumn, które są obecne na liście:
Ponadto w tym scenariuszu, dla uproszczenia, wszystkie wartości są przechowywane jako tekst. Możesz jednak przeczytać o zapisywaniu różnych typów danych w moim innym poście tutaj.
Następnie muszę usunąć z obiektu JSON utworzonego z XML te właściwości, które nie są mapowane do żadnej kolumny na liście i utworzyć JSON, który mógłby zostać użyty jako treść żądania podczas tworzenia nowego elementu. Ten JSON musi mieć następującą strukturę:
[{"FieldName":"NAZWA POLA Z XML"}, {"FieldValue": "WARTOŚĆ POLA Z XML"}, ...]
Robię to za pomocą akcji „Select” i wyrażenia, które sprawdza, czy właściwość istnieje na liście wszystkich kolumn:
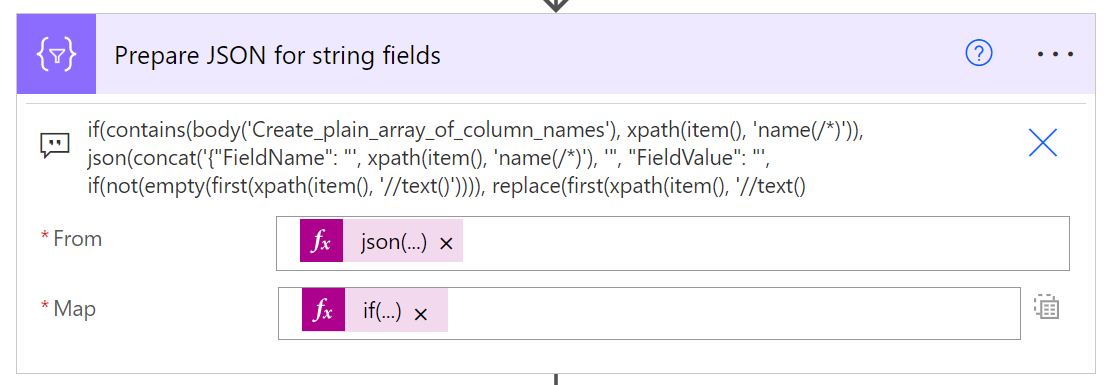
Wyrażenie, którego używam, jest następujące:
if(contains('LIST_OF_COLUMNS', xpath(item(), 'name(/*)')), json(concat('{"FieldName": "', xpath(item(), 'name(/*)'), '", "FieldValue": "', if(not(empty(first(xpath(item(), '//text()')))), replace(first(xpath(item(), '//text()')), '"', '\"'), first(xpath(item(), '//text()'))), '"}')), '')
Następnie proces usuwa wpisy, dla których nie ma pasującej kolumny. Jednak powoduje to pozostawienie pustych wartości w tablicy, co w dalszym ciągu może prowadzić do błędów, gdy dane zostaną użyte do utworzenia elementu. Aby pozbyć się tych pustych elementów, używam akcji „Filter”:

I teraz już, kod JSON jest gotowy do użycia jako treść żądania, która zostanie wysłana do endpointa opisanego na początku posta:
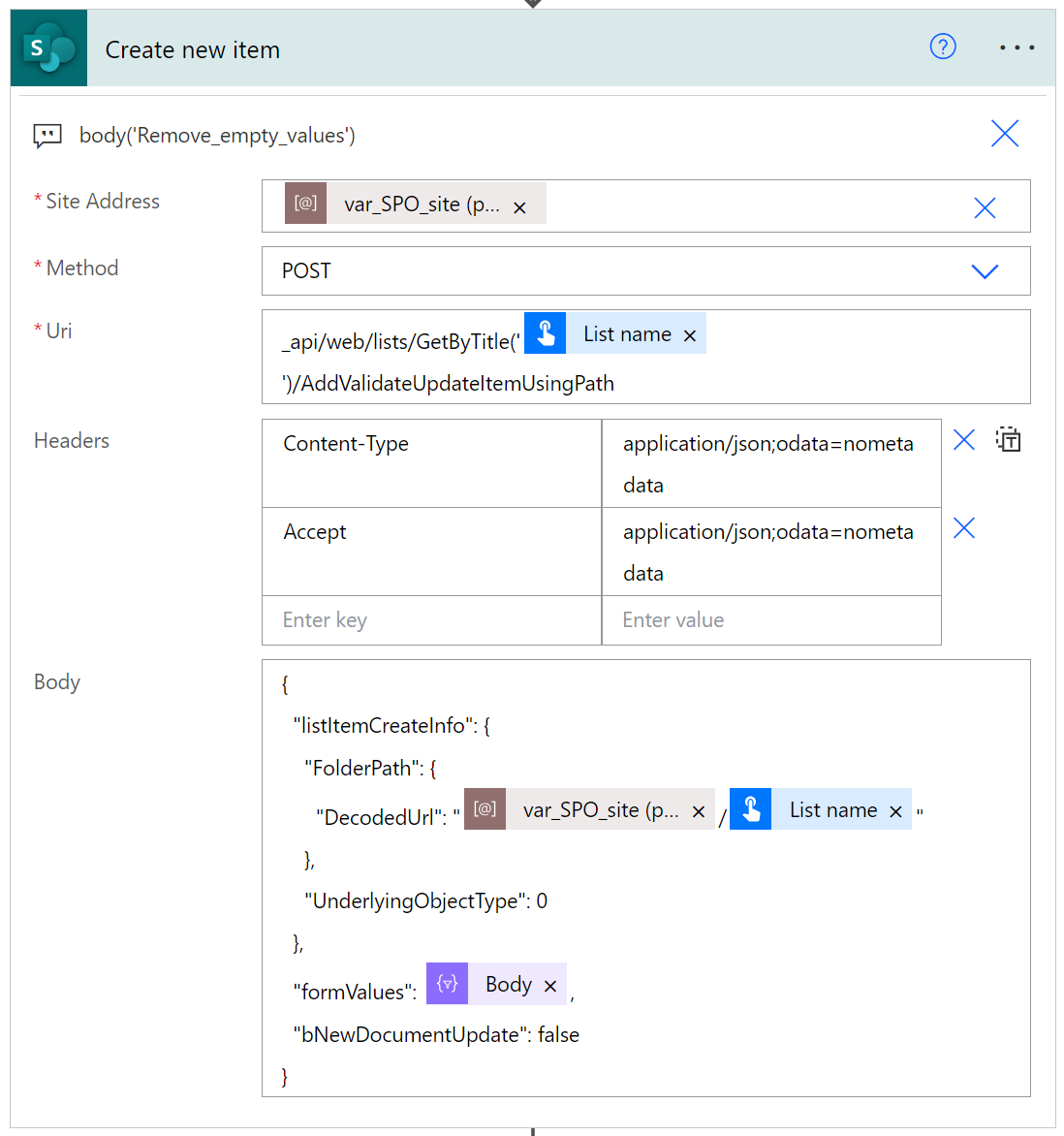
Endpoint: _api/web/lists/GetByTitle('LIST NAME')/AddValidateUpdateItemUsingPath
Treść żądania:
{
"listItemCreateInfo": {
"FolderPath": {
"DecodedUrl": "ABSOLUTE PATH TO THE LIST"
},
"UnderlyingObjectType": 0
},
"formValues": [{"fieldName":"field name", "fieldValue": "field value"}, ...],
"bNewDocumentUpdate": false
}
Następne kroki?
Istnieją dwa możliwe dalsze scenariusze:
- Powiadom właściciela listy, że istnieją dane, które nie zostały zapisane, ponieważ nie było poniższych kolumn, lub
- Stwórz brakujące kolumny.
Spróbuję pokazać każdy z nich, ponieważ są dość podobne.
Jak otrzymać listę brakujących kolumn?
To kluczowy krok w całym rozwiązaniu – proces polega na znalezieniu listy kolumn, które występują jako węzły w pliku XML, a których na liście nie ma. Aby to zrobić, wystarczy utworzyć odwrotne wyrażenie – które usuwa kolumnę z kodu JSON ze wszystkimi danymi z XML, jeśli JEST OBECNA na liście. Można to zrobić, dodając do warunku wyrażenie not(). Wyrażenie jest następujące:
if(not(contains('LIST_OF_COLUMNS', xpath(item(), 'name(/*)'))), json(concat('{"FieldName": "', xpath(item(), 'name(/*)'), '", "FieldValue": "', if(not(empty(first(xpath(item(), '//text()')))), replace(first(xpath(item(), '//text()')), '"', '\"'), first(xpath(item(), '//text()'))), '"}')), '')
Następnie, podobnie jak w krokach opisanych powyżej, proces musi pozbyć się wszystkich pustych wartości. Aby to zrobić, użyję tej samej akcji „Filter”, co powyżej.
I tu musisz dokonać wyboru – powiadomić lub utworzyć. Jeśli po prostu chcesz wysłać powiadomienie, utwórz ładnie wyglądającą listę HTML i wyślij informacje o brakujących kolumnach za pomocą poczty e-mail. Aby przygotować listę użyj następującej akcji „Select”:
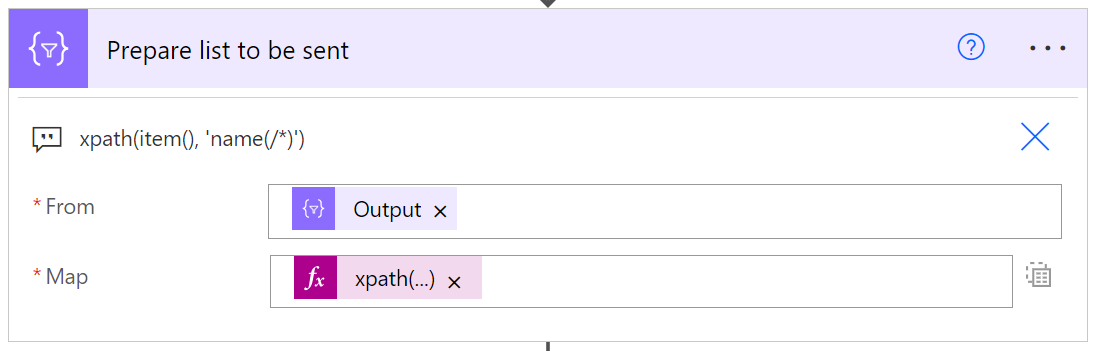
A następnie w akcji “Send an email” opakuj wynik akcji w następujący kod HTML:
<ul><li>join(outputs('Prepare_list_to_be_sent'), '</li><li>')</li></ul>
Jeśli chcesz utworzyć brakujące kolumny przed stworzeniem samego rekordu, tutaj musisz użyć pętli „Apply to each” dla tablicy zbudowanej powyżej. Następnie w każdym uruchomieniu wystarczy wywołać endpoint, aby utworzyć kolumnę na liście. Dla uproszczenia proces utworzy tutaj po prostu kolumnę tekstową, ale możesz dodać więcej logiki, ocenić typ danych i spróbować utworzyć bardziej odpowiednie kolumny, jeśli zajdzie taka potrzeba:
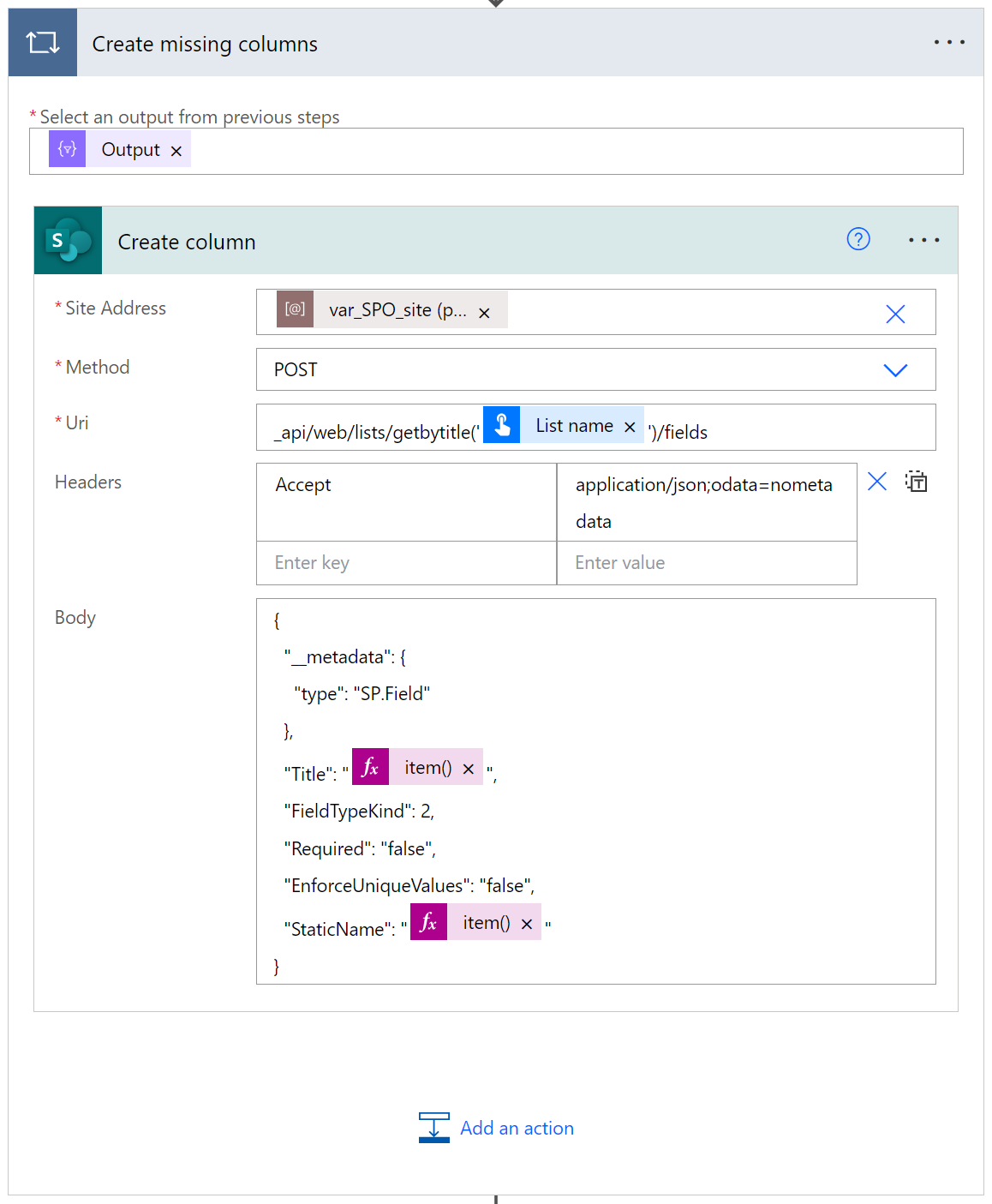
Endpoint: _api/web/lists/getbytitle('LIST NAME')/fields
Treść żądania:
{
"__metadata": {
"type": "SP.Field"
},
"Title": "FIELD NAME",
"FieldTypeKind": 2,
"Required": "false",
"EnforceUniqueValues": "false",
"StaticName": "FIELD NAME"
}
Wartości Field type kind znajdziesz tutaj: FieldType enumeration (Microsoft.SharePoint.Client) | Microsoft Learn
I to wszystko!
Podsumowanie
Dzięki opisanemu powyżej rozwiązaniu możesz naprawdę dynamicznie tworzyć rekordy na listach SharePoint, nawet nie zastanawiając się, czy kolumny są obecne, czy nie. To rozwiązanie uzupełnia rozwiązanie, które opisałem w moim poprzednim poście, dotyczącym dynamicznego udostępniania list i uprawnień. Mam nadzieję, że Ci się spodoba i że pomoże 😉




