

Nintex Forms – ładowanie danych z tabeli z SQL Server do repeating section
Table of Contents
Ten post jest opisem „krok po kroku”, przedstawiającym sposów, w jaki można pobrać dane z tabeli w SQL Server i umieścić je w przygotowanych polach, w kontrolce „Repeating section” w formularzu Nintex. Nie muszę chyba przekonywać, że posiadanie danych w postaci wierszy, w takiej sekcji, pozwoli następnie na tworzenie aplikacji do manipulowania nimi, z uwagi na możliwość przetwarzania każdego wiersza osobno, dzięki zapisywaniu danych z tej kontrolki w formacie XML.
Stworzone przeze mnie rozwiązanie jest nieco bardziej zaawansowane to, opisane tutaj, ponieważ pozwala również na wykonywanie operacji masowych edycji/ usuwania załadowanych danych.
Podstawowe założenia
Rozwiązanie działa realizując poniższe punkty:
- Na formularzu jest umieszczona kontrolka „SQL request”, która przy ładowaniu formularza pobiera wszystkie dane z określonej tabeli.
- Dane są zwracane w formacie XML.
- Wewnątrz formularza znajduje się „Repeating section” z kilkoma zdefiniowanymi polami.
- Skrypt, po uruchomieniu, parsuje kod XML z kontrolki „SQL request” i dla każdego wiersza wprowadza dane do zdefiniowanych pól wewnątrz sekcji powtarzanej.
- Po zakończeniu przetwarzania wiersza, dodaje następny do sekcji i kontynuuje pracę aż do przetworzenia wszystkich danych.
Krok po kroku
First, prepare your repeating section and fill it with fields of your choice. They should correspond to the type of columns inside your SQL Server table, eg. datetime to date control, varchar(50) to text control and unlimited varchars to multiline text control. You can as well place some labels if you’d like to show some data as read-only.
Najpierw dodaj kontrolkę „Repeating section” i wypełnij ją wybranymi polami. Powinny one odpowiadać typom kolumn w tabeli SQL Server, np. kontrola datetime na date, varchar(50) na kontrolkę”Text”, a varchar z nieskończoną liczbą znaków na kontrolkę tekstu wielowierszowego. Możesz także umieścić etykiety, jeśli chcesz pokazać niektóre dane jako tylko do odczytu.

Po drugie, zdefiniuj i ustaw „Control CSS class” dla tych pól. Jest to bardzo ważne dla skryptu, aby umiał wstrzyknąć tekst do odpowiednich pól.
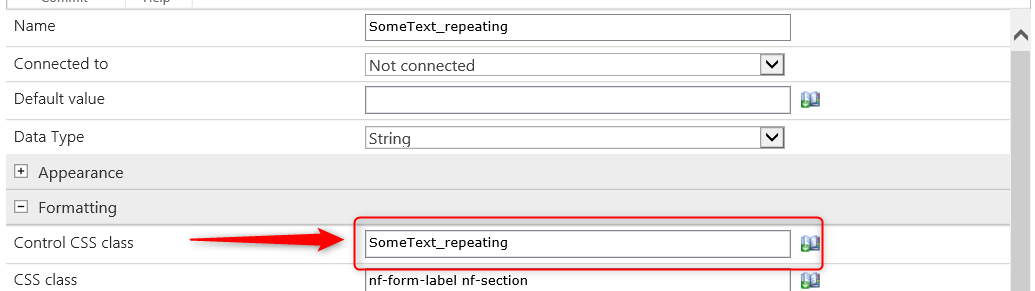
[tds_info] Uwaga! Nie można używać zmiennej JavaScript (JavaScript variable) do przechowywania identyfikatorów kontrolek, ponieważ jest to sekcja powtarzana, dlatego zmienna zachowa tylko ostatni wygenerowany identyfikator.[/tds_info]
Po trzecie, dodaj i skonfiguruj kontrolę „SQL request”. Używam tutaj tego samego podejścia jak dla https://poszytek.eu/nintex/nf2016/wyswietlanie-tabel-z-sql-server-w-nintex-forms/ – używając „FOR XML PATH (” ’)”, wyrażenia dzięki któremu dane z SQL Server są zwracane jako pojedynczy wiersz i kolumna, w formacie XML.
W moim przypadku zapytanie ma następującą postać:
SELECT TOP(1) (
SELECT column1, column2, column3, column4, column5, ...
FROM myTable
ORDER BY column1 FOR XML PATH('record'))
as datatable FROM myTable
Zaś jego wynik są jak poniżej:
<record><column1>AAAAA</column1><column2>2018-10-01T00:00:00</column2><column3>ZZZZZZZ</column3><column4>Some other information 1</column4><column5>AAAA</column5>...</record><record><column1>AAAAA</column1><column2>2018-10-01T00:00:00</column2><column3>ZZZZZZZ</column3><column4>Some other information 1</column4><column5>AAAA</column5>...</record>...I na koniec – skrypt. Jest napisany w jQuery, a jego głównym celem jest parsowanie XML i ładowanie danych do pól wewnątrz powtarzajanej sekcji.
Skrypt
Po uruchomieniu skryptu najpierw przetwarzany jest kod XML:
function buildRepeatingSection (xmlData, loadedRows) {
loadedRows = loadedRows || loadedRowsNo;
var date1 = new Date ();
var date2 = new Date ();
var xmlData = xmlData.match (/<record>(.*?)<\/record>/g);
var parsedData = new Array ();
NWF$.each (xmlData, function (i, val) {
var xmlRowData = NWF$.parseXML (val);
NWF$xmlRowData = NWF$ (xmlRowData);
NWF$column1 = NWF$xmlRowData.find ('column1');
NWF$column2 = NWF$xmlRowData.find ('column2');
NWF$column3 = NWF$xmlRowData.find ('column3');
NWF$column4 = NWF$xmlRowData.find ('column4');
NWF$column5 = NWF$xmlRowData.find ('column5');
parsedData[i] = new Array (
sectionClass,
NWF$column1.text (),
NWF$column2.text (),
NWF$column3.text (),
NWF$column4.text (),
NWF$column5.text ()
);
});
noOfRows = parsedData.length;
dataArray = parsedData;
NWF$ ('.StatusLabel label').text ('Number of loaded rows: 0 / ' + noOfRows);Następnie, po sparsowaniu danych, funkcja wywołuje drugą, która obsługuje ładowanie danych do sekcji powtarzalnej. Wywołanie funkcji „processRowsDataArray” przekazuje sparsowane dane i czas pojedynczego uruchomienia, wraz z definicjami dwóch funkcji zwrotnych (callback) – jedna wywoływana po dodaniu każdego wiersza, druga – po dodaniu wszystkich wierszy.
/* Call of the function that gets created array from SQL and processes it to add rows to repeating section */
processRowsDataArray (dataArray,timeOfSingleRun,
function () {
date2 = new Date ();
NWF$ ('.StatusLabel label').html (
'Number of loaded rows: ' +
currentRow +
' / ' +
noOfRows +
'<br/>Time elapsed (seconds): ' +
(date2 - date1) / 1000
);
},
function () {
/* remove last, empty row, as it is always empty */
NWF$ ('.repeatingSection .nf-repeater-row:last')
.find ('.nf-repeater-deleterow-image')
.click ();
/* hide the "add new row" link */
NWF$ ('.repeatingSection')
.find ('.nf-repeater-addrow')
.css ('visibility', 'hidden');
dataLoaded = true;
}
);
}Funkcja „processRowsDataArray” jest budowana przy użyciu wzorca, który umożliwia działanie asynchroniczne dla funkcji synchronicznych. Wykorzystuje funkcję „timeout” do podziału zakresu danych do dodania na mniejsze porcje, dzięki czemu UI (szczególnie w Internet Explorerze) nie stwarza wrażenia całkowicie 🙂
Funkcja działa w pętli, aż do przekroczenia limitu czasu dla pojedynczego uruchomienia lub gdy liczba wszystkich wierszy do przetworzenia zostanie osiągnięta. Dzięki temu skrypt może działać asynchronicznie:
function processRowsDataArray(array, maxTimePerRow, callback, finished) {
maxTimePerRow = maxTimePerRow || timeOfSingleRun;
function now() {
return new Date().getTime();
}
function addRow() {
var startTime = now();
while (currentRow < array.length && (now() - startTime) <= maxTimePerRow) {
var i = currentRow;
NWF$(".repeatingSection .nf-repeater-row:last").find('input.column1').val(array[i][1]);
NWF$(".repeatingSection .nf-repeater-row:last").find('input.column2').val(array[i][2]);
NWF$(".repeatingSection .nf-repeater-row:last").find('.column3 input').val(array[i][3]);
NWF$(".repeatingSection .nf-repeater-row:last").find('.column4').val(array[i][4]);
NWF$(".repeatingSection .nf-repeater-row:last").find('.column5 input').val(array[i][5]);
/* remove image for row deletion */
if (hideNativeRepeatingSectionControlls)
NWF$(".repeatingSection .nf-repeater-row:last").find('.nf-repeater-deleterow-image').css("visibility", "hidden");
/* add next row */
NWF$(".repeatingSection").find('a').click();
currentRow += 1;
callback.call();
}
if (currentRow < array.length && currentRow < maxRows) {
setTimeout(addRow, 1);
}
else {
finished.call();
}
}
addRow();
}Wyniki
Poniższe nagranie pokazuje, jak działa moje rozwiązanie. W Internet Explorerze parsowanie XML i ładowanie go do sekcji powtarzalnej działa bardzo wolno. Dlatego też dodałem funkcjonalność, która dzieli zakres na mniejsze, 40-rzędowe porcje (dla wersji prezentowanej zmieniłem je na 5), aby użytkownik mógł zdecydować, czy załadować więcej, czy nie:
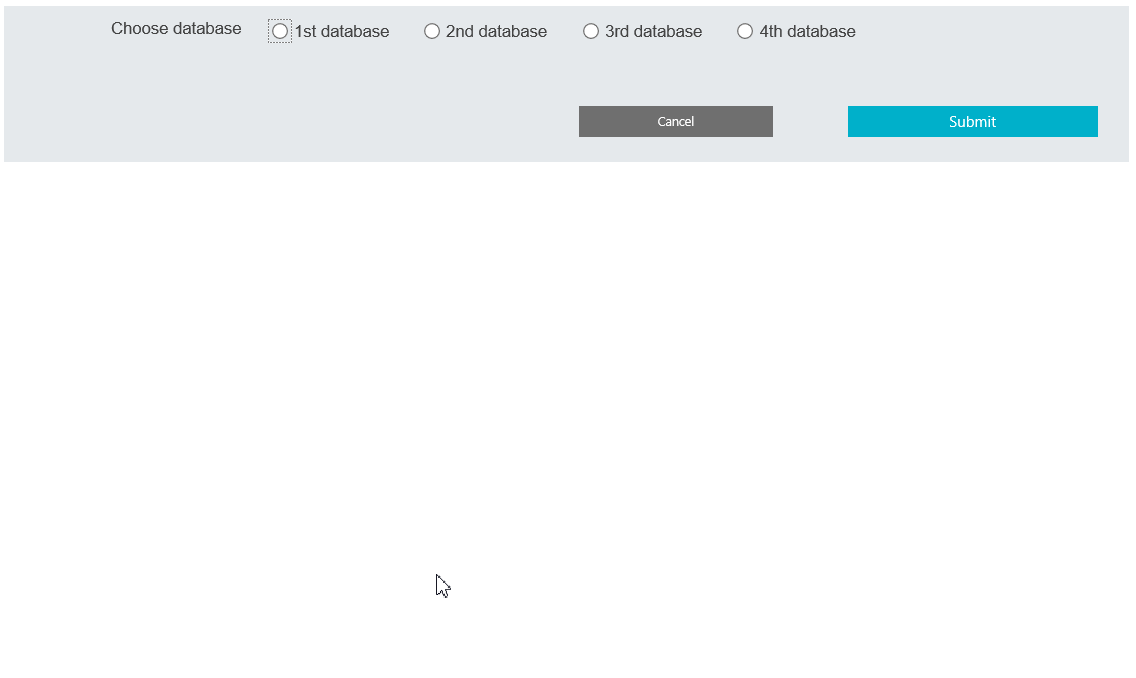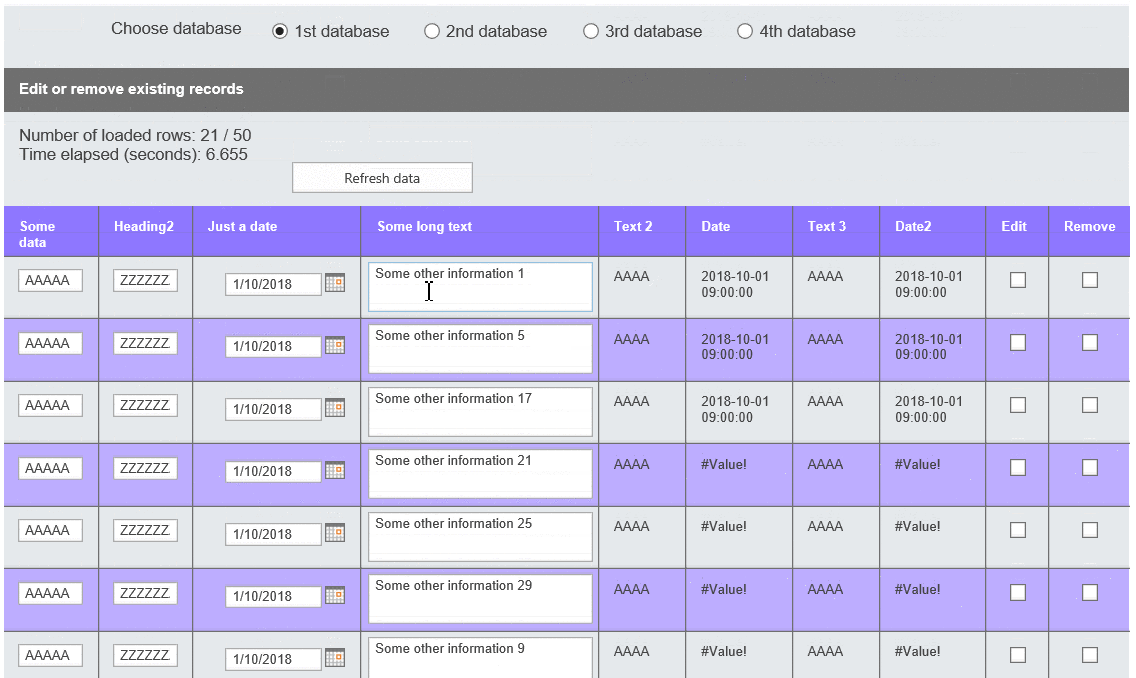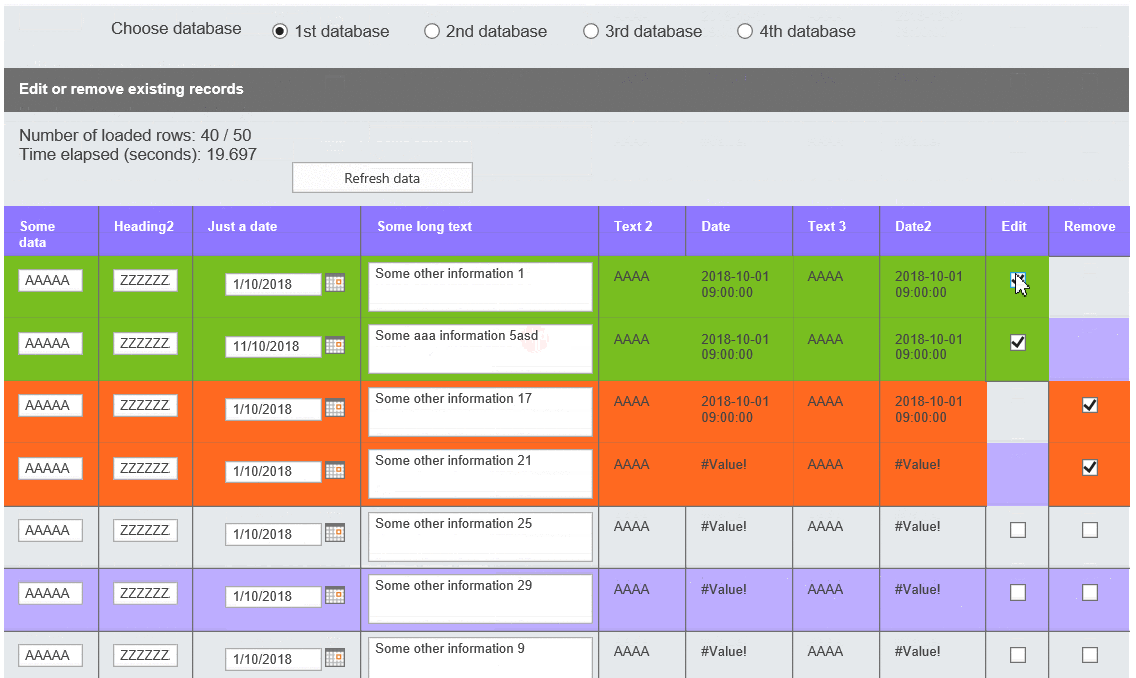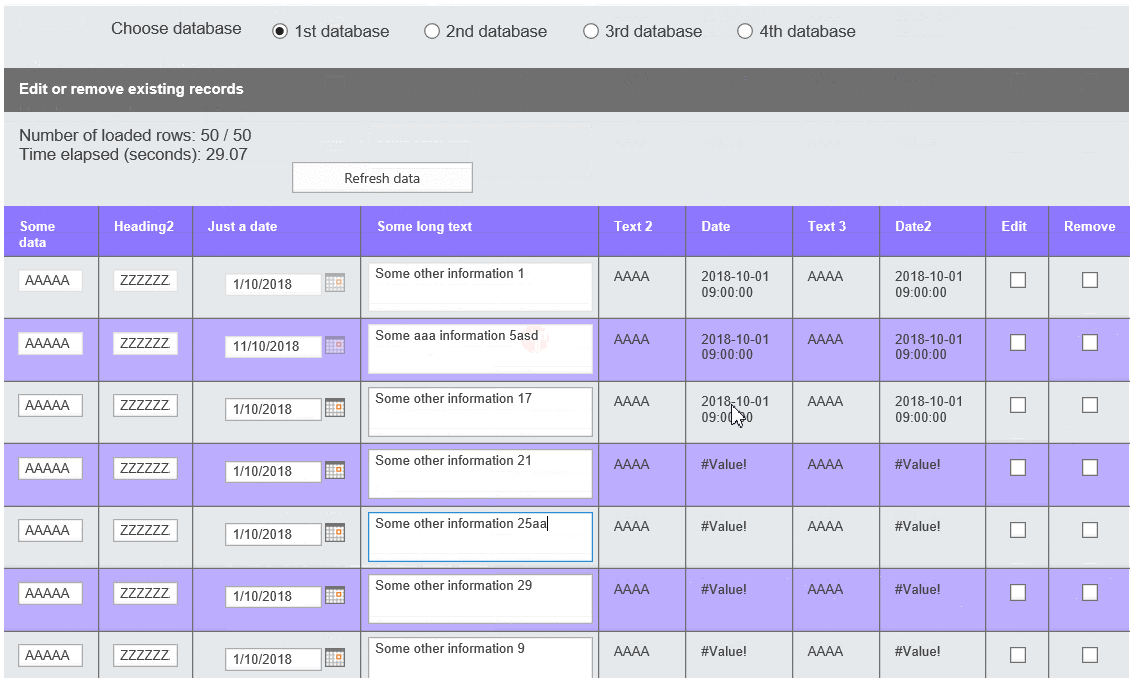
Działający przykład w IE
Uwagi końcowe
Uważam, że warto zwrócić uwagę na fakt, że to rozwiązanie działa inaczej w najpopularniejszych przeglądarkach. Jest to szczególnie związane z czasem wykonania (ładowania).
Najszybszym jest Chrome. Ładowanie 200 wierszy zajmuje około 2 sekund. Edge potrzebuje na to samo zadanie około 17 sekund. Tymczasem Internet Explorer … cóż … w moich testach dobił niemal do 6 minut !
I ostatnia kwestia: jeśli chcesz użyć tego rozwiązania do pracy z dużymi zbiorami danych, uważam, że nie jest ono do tego odpowiednie. Zwłaszcza nie w IE 🙂 Może rozważ PowerApps lub inne podejście do ładowania danych do formularza (bez przetwarzania ich do sekcji powtarzalnej). Zwróć uwagę, że jest to bardzo czasochłonne zadanie dla przeglądarki.


