

Obejście limitu 2000 elementów dla funkcji Collect w Power Apps
Spis treści:
To będzie krótki post. Chcę podzielić się z Wami moim podejściem do obejścia progu zwanego limitem wierszy danych (row data limit), który uniemożliwia funkcji „Collect” uzyskanie większej liczby pozycji niż ta, określona w ustawieniach. Źródłem danych w moim przypadku jest SharePoint.
Inspiracją do stworzenia tego kodu była sugestia @mrdang na jednym z for PowerUsers, gdzie zasugerował pobieranie danych w partiach. Także stworzyłem swoją, udoskonaloną i krótszą wersję tamtej roboczej idei.
Podstawy
Dla niektórych użytkowników prawdziwą niespodzianką jest fakt, gdy dowiadują się, że funkcje Collect i ClearCollect są w rzeczywistości… niedelegowalne. Dlatego w przypadku korzystania z funkcji Collect(źródło danych) maksymalna liczba zwracanych wierszy jest ograniczona przez ustawienie limitu wierszy danych:
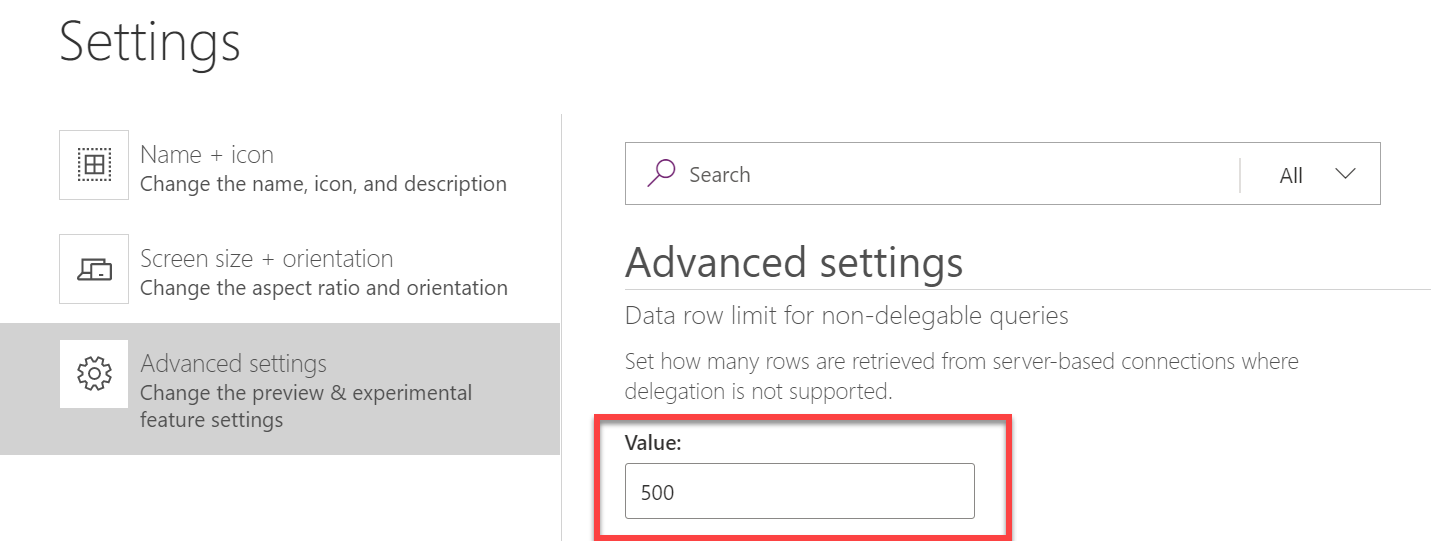
Domyślnie jest to ustawione na 500 i można to zwiększyć do maks. 2000.
W moim przypadku powodem, dla którego musiałem załadować więcej danych do kolekcji było to, że później w aplikacji musiałem wykonywać złożone operacje filtrowania, których również nie można było delegować, więc bez zastosowania tego tricku, ostatecznie nigdy nie otrzymałbym danych, których oczekiwałem.
Wymagania wstępne
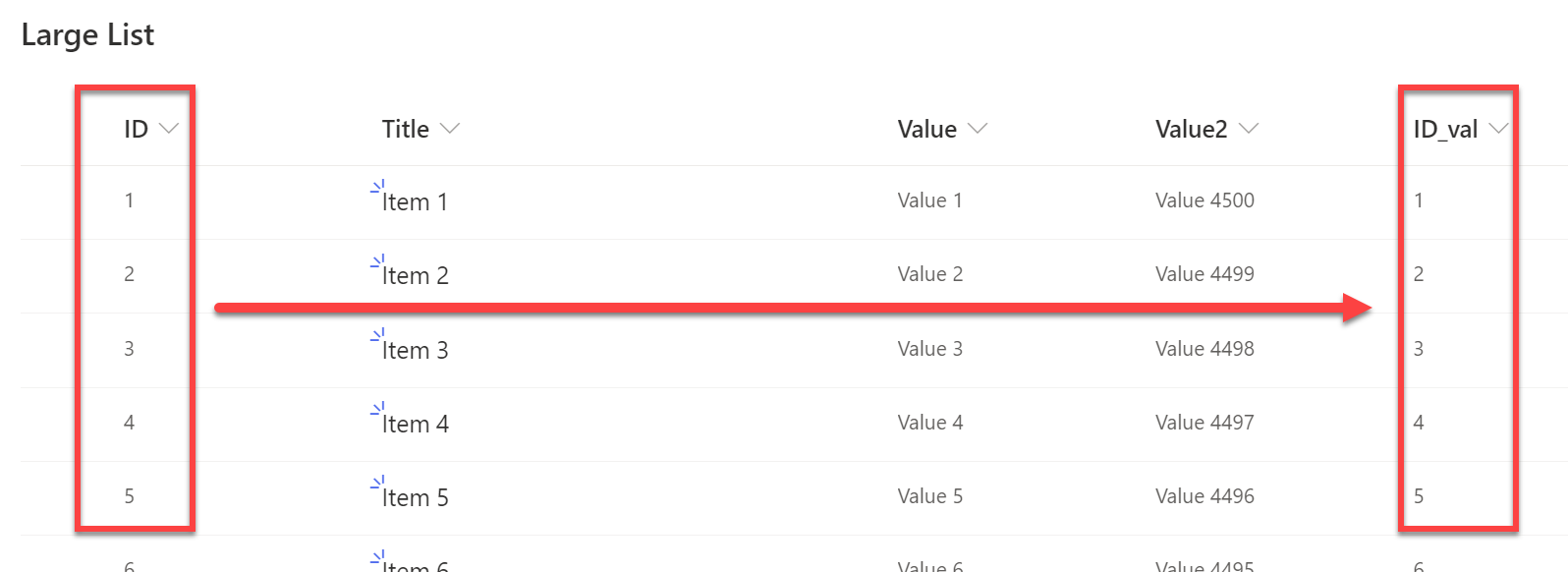
Jedynym minusem mojego rozwiązania, który jest właściwy tylko dla SharePoint, jest fakt, że kolumna ID nie może być używana do porównań zakresów (większy niż, mniejszy niż, itp.), ponieważ użycie go w tym celu powoduje, że całe zapytanie nie jest delegowalne (źródło). Jeśli korzystasz z innych źródeł, takich jak CDS lub SQL Server, nie powinno to stanowić problemu.
Tak więc w przypadku SharePoint musisz stworzyć/ użyć innej kolumny typu liczbowego, która ma te same wartości, co wartości w odpowiadające jej kolumnie ID.
Niestety, nie jest też możliwe użycie do tego celu kolumny obliczeniowej, ponieważ nawet jeśli jest ona ustawiona na „Numer”, usługa Power Apps nadal rozpoznaje ją jako tekst i nie pozwala na użycie w porównaniach zakresów.
No to jak to zrobić?
Najpierw musisz obliczyć liczbę iteracji, które będą wymagane do pobrania wszystkich danych ze źródła danych. Aby to zrobić, pobieram wartości ID pierwszego i ostatniego rekordu. Następnie dzielę ich różnicę przez liczbę wierszy, które mają zostać zwrócone przez jedną iterację. Ta liczba nie może być oczywiście większa niż ustalony limit danych w wierszach 🙂
Set(
firstRecord,
First('Large List')
);
Set(
lastRecord,
First(
Sort(
'Large List',
ID,
Descending
)
)
);
Set(
iterationsNo,
RoundUp(
(lastRecord.ID - firstRecord.ID) / 500,
0
)
);
Collect(iterations, Sequence(iterationsNo,0));
Ostatnim krokiem jest utworzenie kolekcji, w której każdy element jest kolejnym numerem iteracji. Więc np. jeśli mam 1000 rekordów i chcę je pobrać po 500 w każdej iteracji, będę miał dwie iteracje, więc kolekcja iterations będzie zawierać: [0, 1].
Następnie dla każdej iteracji obliczam dolną i górną granicę, aby pobrać elementy z identyfikatorami pomiędzy. Więc np. dla pierwszej iteracji będę potrzebować elementów o ID pomiędzy 0 a 500:
ForAll(
iterations,
With(
{
prevThreshold: Value(Value) * 500,
nextThreshold: (Value(Value) + 1) * 500
},
If(
lastRecord.ID > Value,
Collect(
LargeListSP,
Filter(
'Large List',
ID_val > prevThreshold && ID_val <= nextThreshold
)
)
)
)
);
Wyrażenie Filter używające kolumny Numeric do porównań zakresów jest delegowalne, więc nie powoduje żadnych problemów 🙂 I to wszystko. Postępując zgodnie z tym wzorcem, możesz pobierać partiami tysiące elementów z dowolnego źródła danych. Wartość ID_val w moim przypadku to właśnie dodatkowa kolumna, z wartościami takimi jak odpowiadające im wartości w kolumnie ID.
Tak to wygląda w akcji:
Nie, nie mam pojęcia, dlaczego liczba wierszy pokazuje o 3 elementy mniej niż w rzeczywistości, ale cóż … Nic nie jest idealne 🙂


Aleks
Czy jeżeli będą luki w ID (bo zostaną usunięte jakieś wiersze na liście SP) to może wystąpić jakiś błąd?
Tomasz Poszytek
Nie, bo ta technika działa na zakresie wartości ID. Najwyżej w danym batchu zostanie pobranych mniej elementów niżw takim, gdzie wszystkie rekordy z zakresy są obecne.