

How to: Przenoszenie/ kopiowanie załączników z InfoPath do SharePoint Online
Spis treści:
Pomimo faktu, iż InfoPath już wielokrotnie został uśmiercony, a jego przyszłość definitywnie zakończona, dla wielu firm budowanie formularzy dla przepływów pracy, z użyciem tego narzędzia, jest czymś tak oczywistym jak praca z Excel. Jednakże, gdy formularze są tworzone dla rozwiązań pracujących w Office 365 i SharePoint Online, ograniczenia i limity formularzy InfoPath są bardzo widoczne i stają się prawdziwym problemem.
Jakiś czas temu zmagałem się z problemem przekraczania dopuszczalnego rozmiaru instancji workflow (tutaj), który to był bezpośrednio związany z wielkością formularza InfoPath wraz z rozmiarem dołączonych do niego plików. Najbardziej oczywistym rozwiązaniem, jakie wówczas przyszło mi do głowy, było przeniesienie załączników z formularza do biblioteki dokumentów w SharePoint, jednak jak się okazało, nie było to łatwe do zrobienia z uwagi na algorytm, jaki jest używany w InfoPath do obsługi załączników.
Jak InfoPath obsługuje załączniki?
Pliki dodane do formularza InfoPath są bezpośrednio wstawiane do struktury XML formularza, po zakodowaniu ich do ciągu znaków Base64:
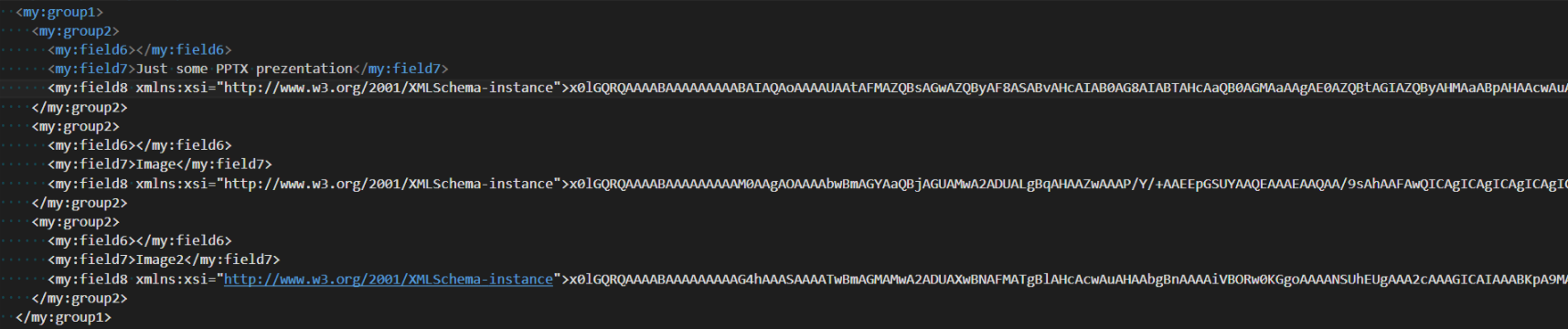
Co się jednak okazało: InfoPath nie tylko koduje samą zawartość pliku, ale dodaje także kilka informacji: nagłówek, zawierający takie dane jak: wielkość, wersja, długość nazwy pliku oraz samą nazwę pliku.
Chociaż wielkość nagłówka jest stała, zawsze zawiera 24 bajty, o tyle już wielkość zarezerwowana dla nazwy pliku jest różna, zależna naturalnie od jej długości. Ta dodatkowa liczba bajtów jest przechowywana w postaci wartości DWORD, w bajcie nr 20. Sama nazwa pliku zaś jest kodowana do Unicode, zatem długość musi być przemnożona przez 2.
Zatem, aby móc odseparować faktyczną zawartość pliku od nagłówka i jego nazwy, ciąg Base64 musi zostać zdekodowany do tablicy bajtów, następnie pierwszych 24 bajty oraz długość nazwy pliku * 2 muszą zostać „odcięte”.
Przeczytaj więcej na temat programistycznego podejścia do kodowania i dekodowania załączników InfoPath tutaj: https://support.microsoft.com/en-us/help/892730/how-to-encode-and-decode-a-file-attachment-programmatically-by-using-v
Szukając rozwiązania
Szukając możliwego wyjścia z sytuacji naturalnie w pierwszej kolejności zwróciłem się do produktów Nintex. Jednak tutaj nie znalazłem żadnych akcji, które pozwoliłyby mi na zdekodowanie Base64 do strumienia binarnego, co jest konieczne do fizycznego utworzenia pliku. Następnie wziąłem na tapet Microsoft Flow. Zrobił na mnie duże wrażenie posiadaną mnogością funkcji służących do konwertowania danych pomiędzy różnymi typami. I znalazłem również funkcję pozwalającą na konwersję ciągu Base64 do strumienia binarnego.
Jednakże po chwili pierwszej euforii utknąłem na innym problemie – jak odciąć ów nieszczęsny nagłówek i nazwę pliku od jego treści? Ponieważ nie jest to wartość stała, nie mogłem obliczyć ile znaków z ciągu powinienem usunąć (korzystając z prostych kalkulacji wiedząc, że każdy znak w Base64 odpowiada 6 bitom, a 8 bitów to 1 bajt, itd…). Niestety, Flow nie posiada także funkcji, pozwalającej na zapis ciągu binarnego do tablicy bajtów.
I nagle mnie olśniło! Otworzyłem portal Azure i przeszedłem do „Function Apps”. Ta usługa naprawdę umożliwia rozszerzyć wbudowane możliwości Flow i Logic Apps (również przepływów pracy w Nintex) o operacje dotąd niedostępne.
Czym są Azure Function?
W zasadzie jest to po prostu usługa, pozwalająca na wykonywanie małych kawałków kodu: funkcji, metod w chmurze. Istnieją dwa sposoby rozliczania kosztów: per uruchomienie („per consumption”, tutaj mogą występować pewne opóźnienia, cennik) lub jako hostowana usługa („app service”, bezpośrednio na jednej z maszyn wirtualnych posiadanych w Azure).
Kolejną super kwestią dotyczącą Azure Functions jest mnogość języków, w jakich można tworzyć kod. Do wyboru są m. in. JavaScript, TypeScript, PHP, Python, Bash i naturalnie: C# i F# (źródło). Kod można pisać korzystając z wbudowanego edytora lub poprzez Visual Studio (źródło).
Następnie, funkcje można uruchamiać w różnoraki sposób (źródło). Ja użyłem „HTTP trigger”, dzięki czemu mogłem używać funkcji poprzez akcję „HTTP Request”.
Rozwiązanie
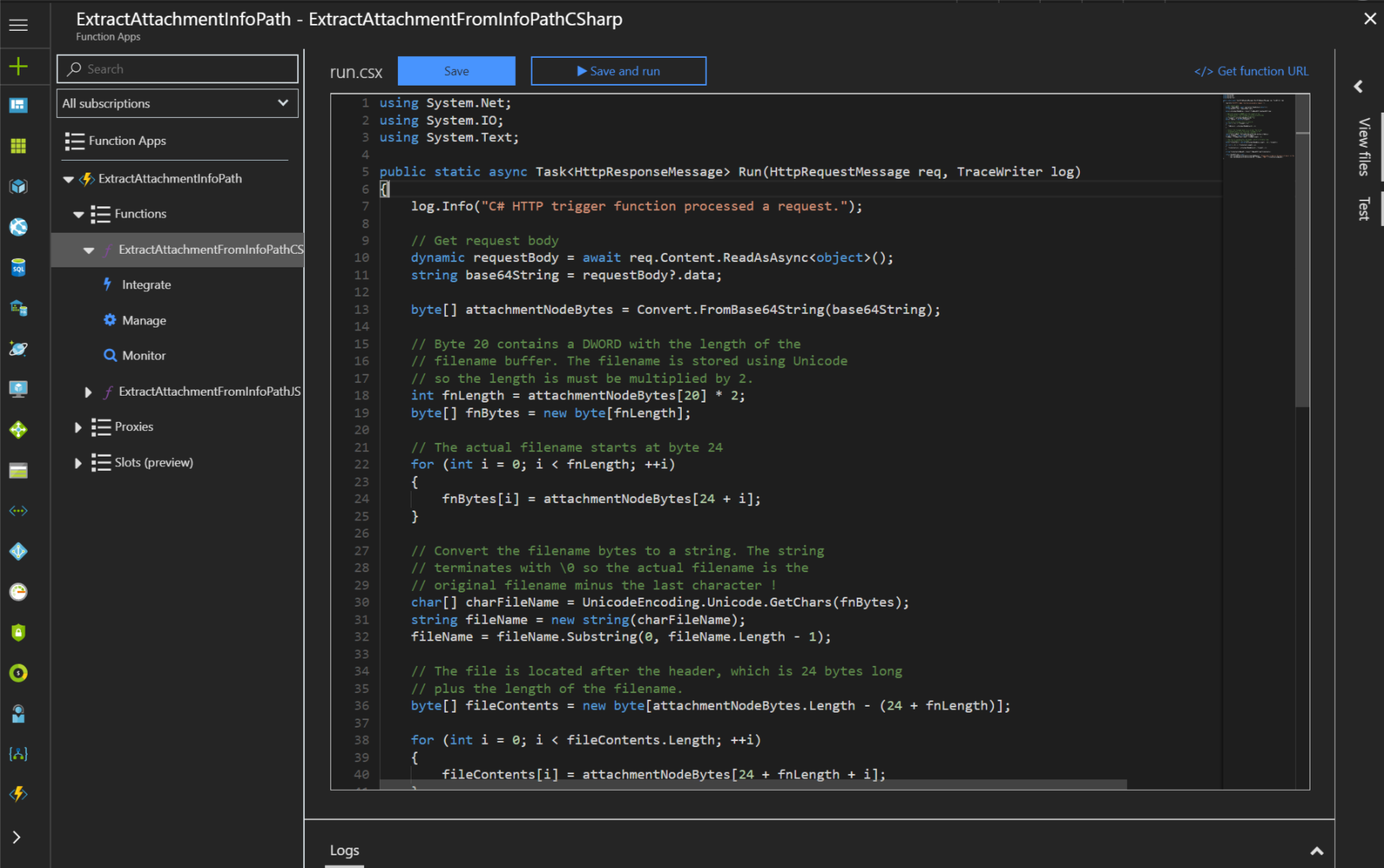
Napisałem prostą funkcję w C#, która wykonuje następujące kroki:
- Odbiera ciąg znaków Base64 z żądania POST;
- Dekoduje go do tablicy bajtów, wyodrębnia nagłówek i nazwę pliku;
- Koduje zawartość pliku z powrotem do ciągu znaków Base64;
- Zwraca nazwę pliku wraz z ciągiem Base64 z powrotem do nadawcy żądania.
Kod jest bardzo prosty, napisany w oparciu o informacje z Technet:
using System.Net;
using System.IO;
using System.Text;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
// Get request body
dynamic requestBody = await req.Content.ReadAsAsync<object>();
string base64String = requestBody?.data;
byte[] attachmentNodeBytes = Convert.FromBase64String(base64String);
// Byte 20 contains a DWORD with the length of the
// filename buffer. The filename is stored using Unicode
// so the length is must be multiplied by 2.
int fnLength = attachmentNodeBytes[20] * 2;
byte[] fnBytes = new byte[fnLength];
// The actual filename starts at byte 24
for (int i = 0; i < fnLength; ++i)
{
fnBytes[i] = attachmentNodeBytes[24 + i];
}
// Convert the filename bytes to a string. The string
// terminates with \0 so the actual filename is the
// original filename minus the last character !
char[] charFileName = UnicodeEncoding.Unicode.GetChars(fnBytes);
string fileName = new string(charFileName);
fileName = fileName.Substring(0, fileName.Length - 1);
// The file is located after the header, which is 24 bytes long
// plus the length of the filename.
byte[] fileContents = new byte[attachmentNodeBytes.Length - (24 + fnLength)];
for (int i = 0; i < fileContents.Length; ++i)
{
fileContents[i] = attachmentNodeBytes[24 + fnLength + i];
}
string fileContentsInBase64 = Convert.ToBase64String(fileContents);
return base64String == null
? req.CreateResponse(HttpStatusCode.BadRequest, "Please pass a name on the query string or in the request body")
: req.CreateResponse(HttpStatusCode.OK, fileName + "###" + fileContentsInBase64);
}
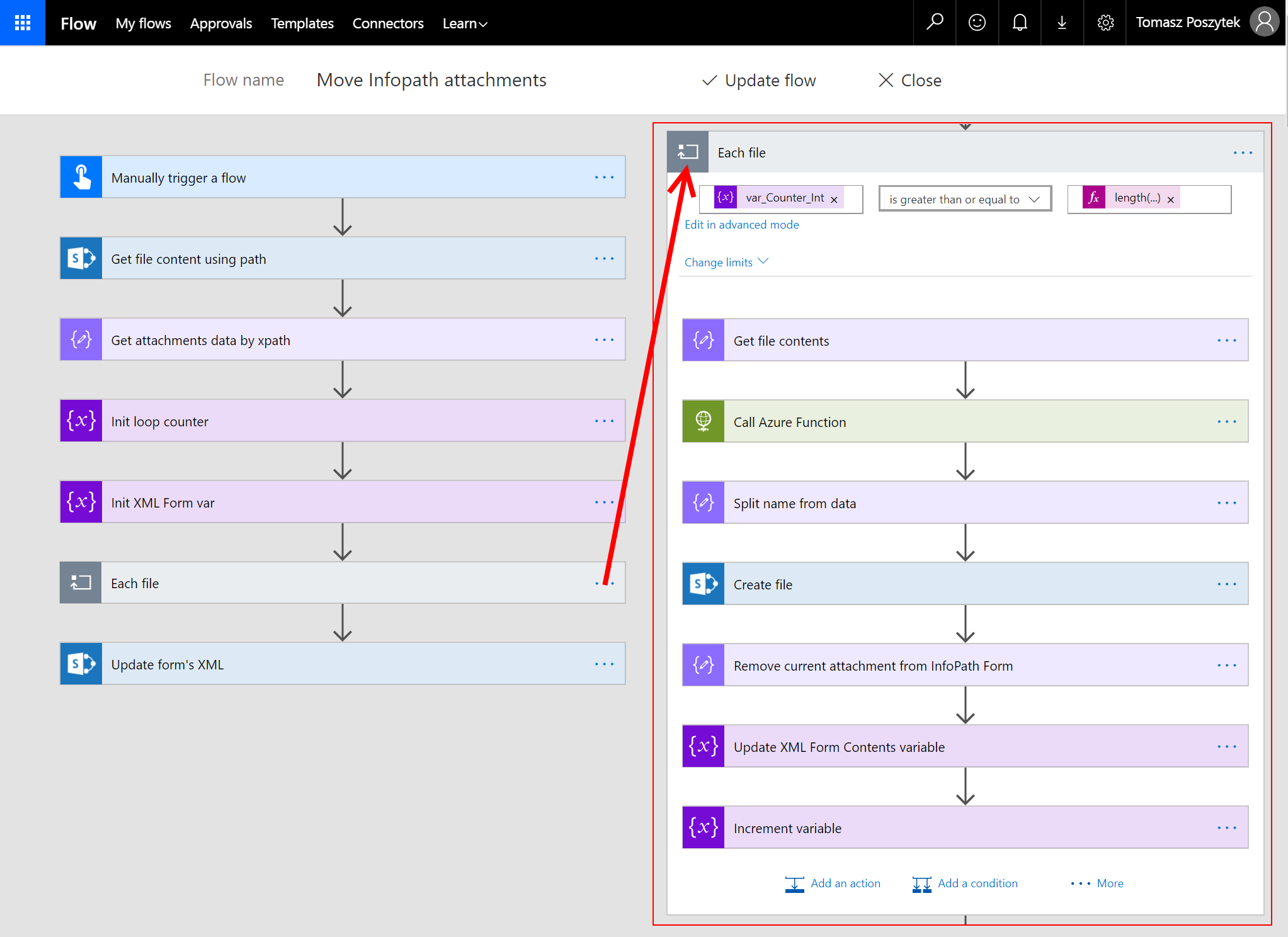
Sam Flow również nie jest skomplikowany. Wykonuje poniższe kroki:
- Odbiera żądanie HTTP zawierające następujące dane: nazwę pliku InfoPath, nazwę pola przechowującego załączniki i nazwę docelowej biblioteki dokumentów;
- Odczytuje zawartość pliku formularza, używa xpath do pozyskania listy ciągów Base64 i zapisuje je do tablicy;
- Dla każdego elementu z tablicy woła moją Azure Function, która oddziela nagłówek i nazwę pliku od jego zawartości;
- Tworzy plik w docelowej bibliotece, używając pozyskanej od funkcji nazwy pliku i jego zawartości (konwertując w locie ciąg Base64 do strumienia binarnego);
- I na koniec zamienia ciąg Base64 w formularzu na pusty string, dzięki czemu usuwa załącznik z formularza.
Wyrażenie używające funkcję xpath służące do uzyskania listy załączników jest następujące:
xpath(xml(body('Get_file_content_using_path')), concat('//*[contains(local-name(), "', triggerBody()['text_1'], '")]/text()'))
Gdzie „text_1” to parametr wejściowy przepływu, zawierający nazwę kontrolki załączników.
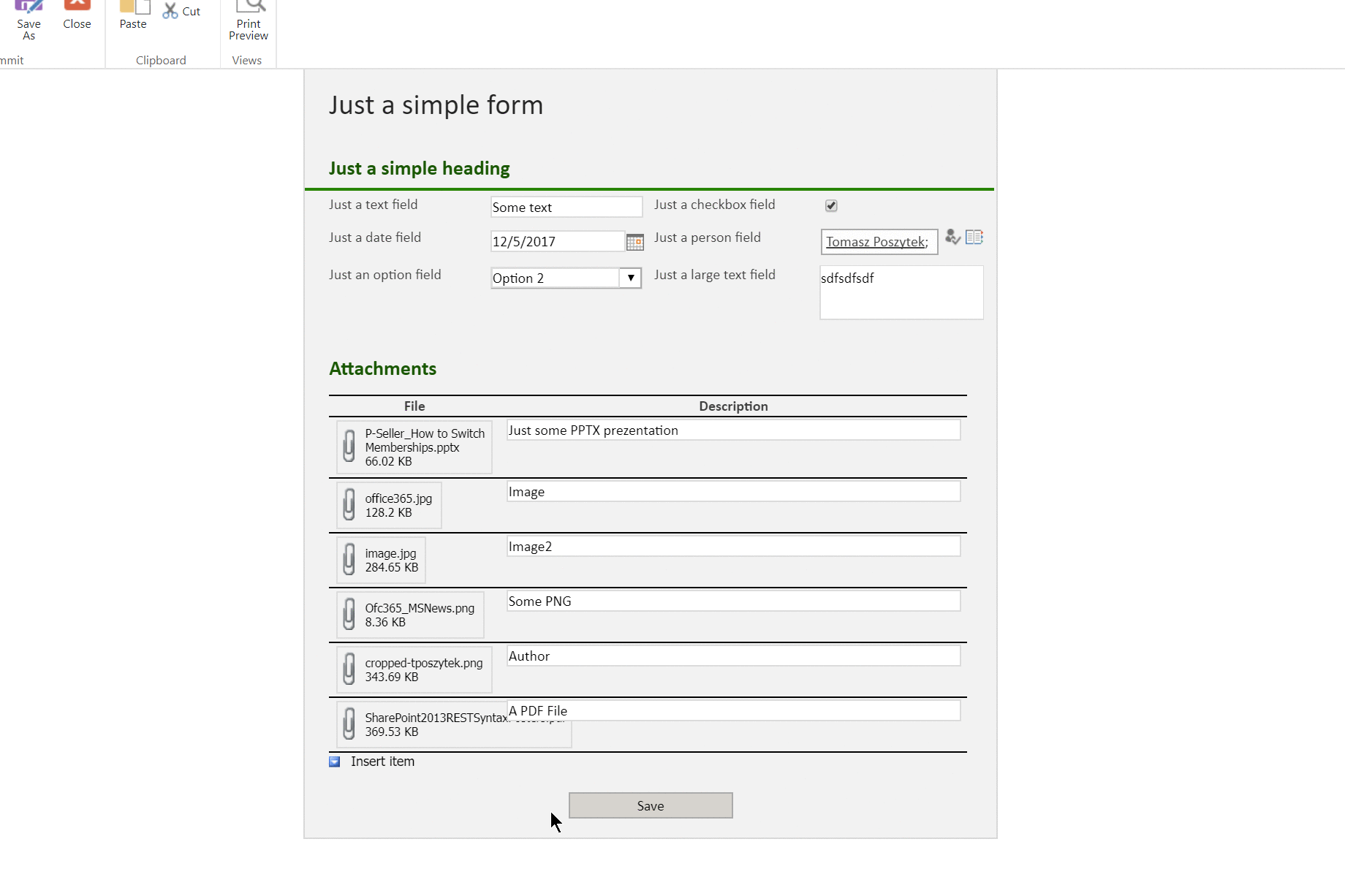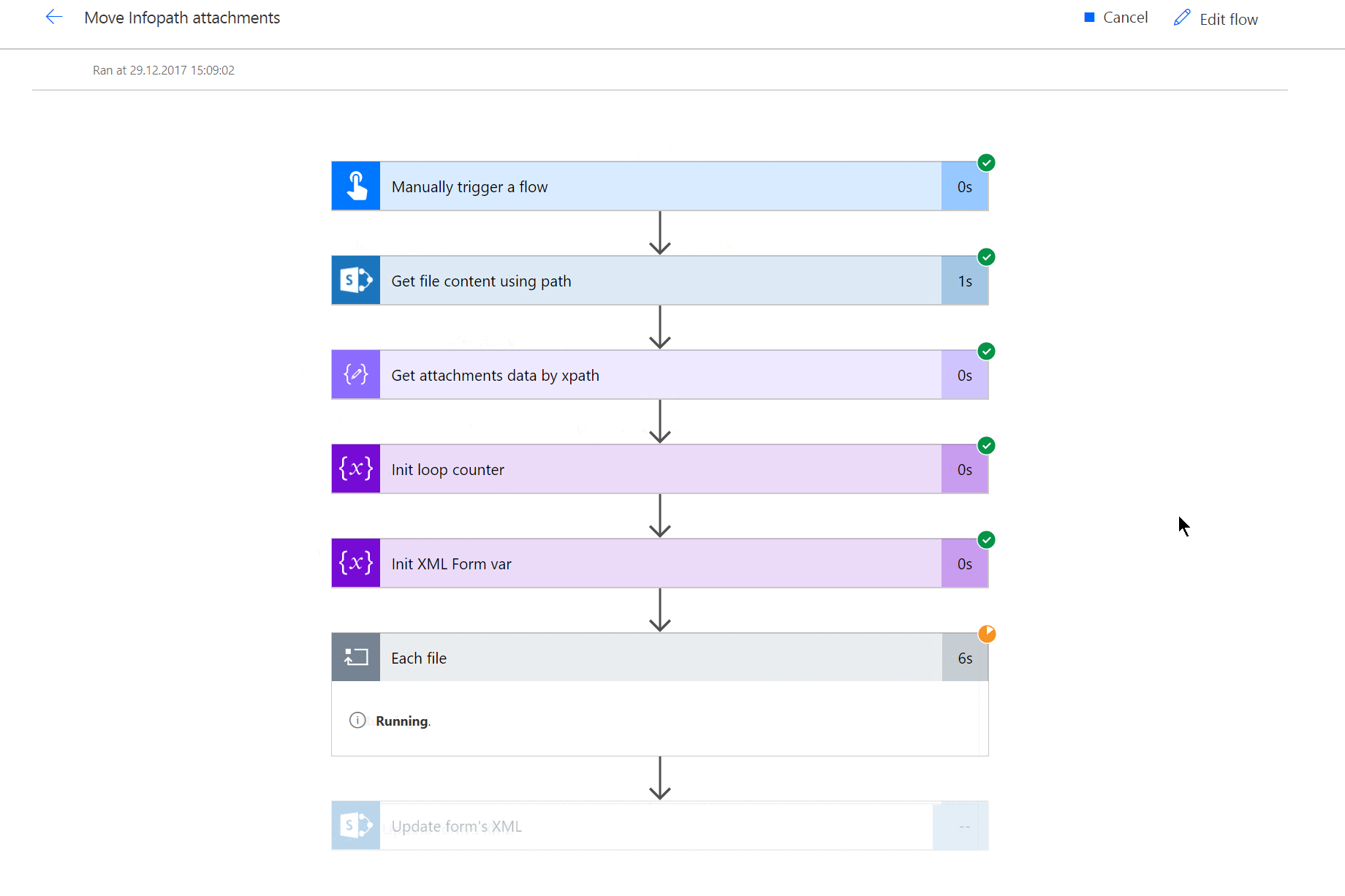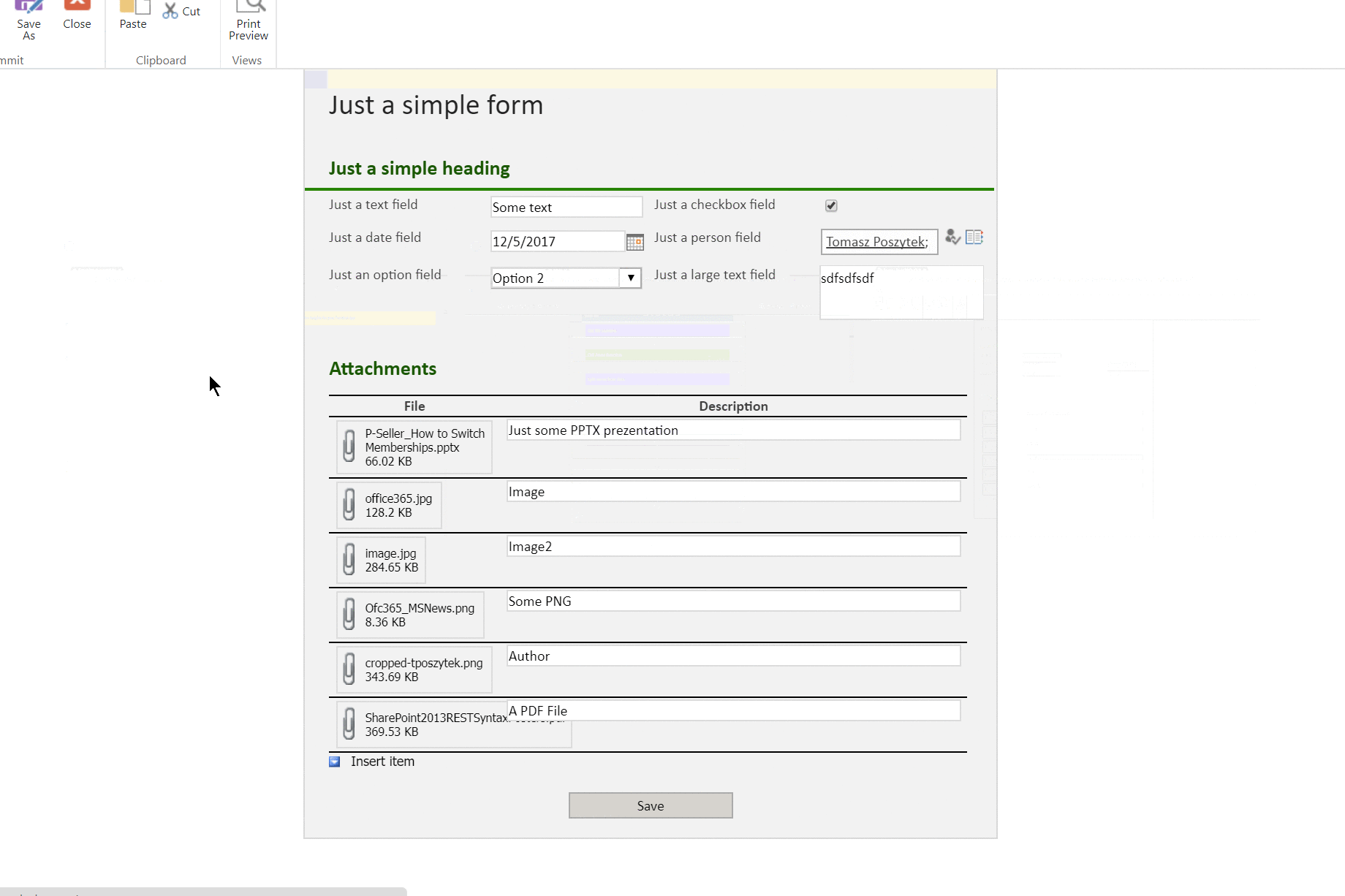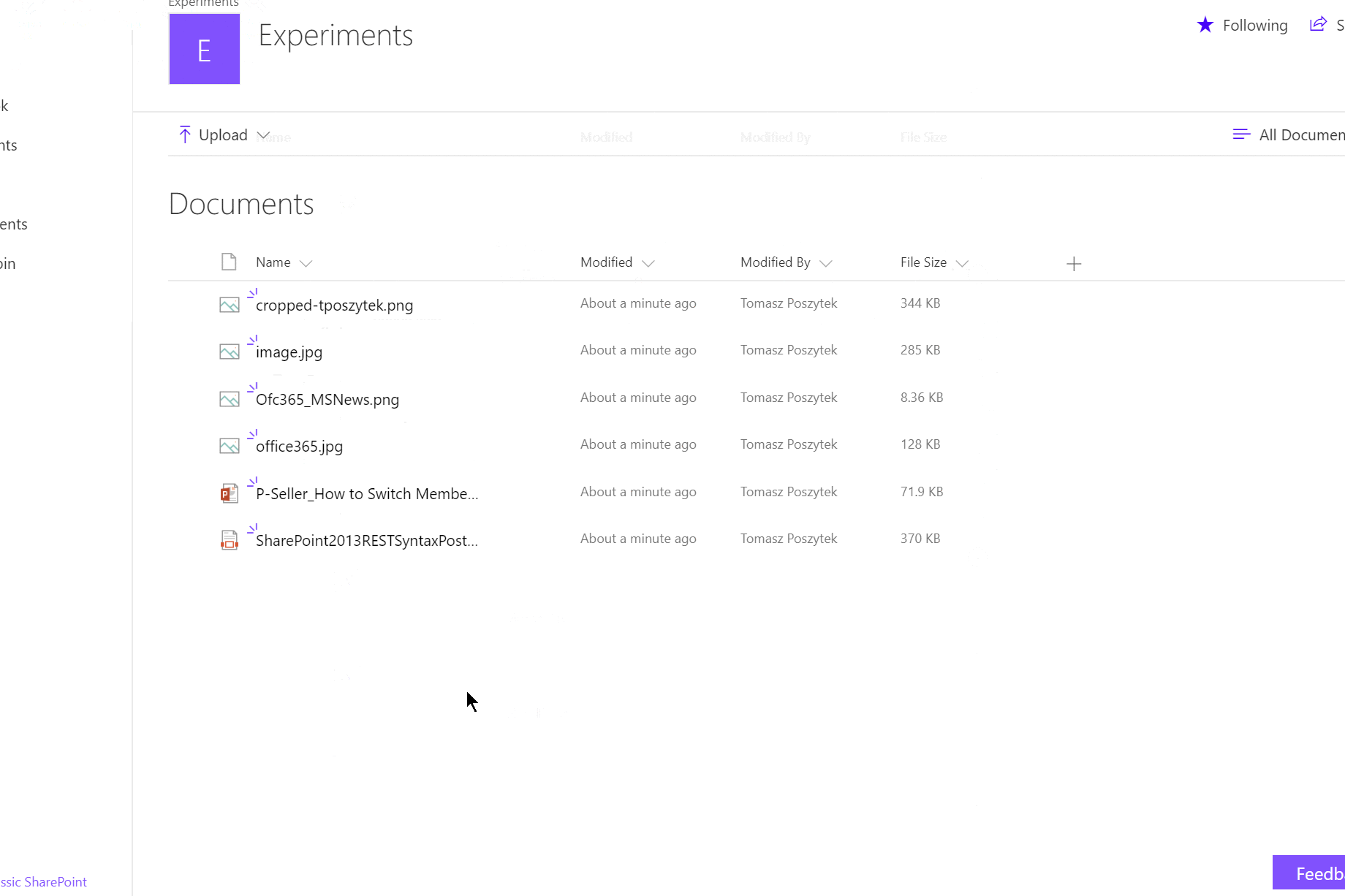
Wynik działania (tak wiem, że historia uruchomień Azure Function nie odświeżyła się gdy ją wyświetliłem, ale serio – funkcja się uruchomiła):
Możliwy rozwój rozwiązania
Następne kroki, na ścieżce rozwoju rozwiązania:
- Wstawianie linku do przeniesionego pliku do pola w formularzu, powiązanego z przenoszonym plikiem;
- Tworzenie podfolderów w docelowej bibliotece – dla każdego formularza może zostać utworzony podfolder o nazwie formularza, dla przechowywania plików pochodzących z niego.
Podoba Ci się to rozwiązanie? Podziel się komentarzami!




